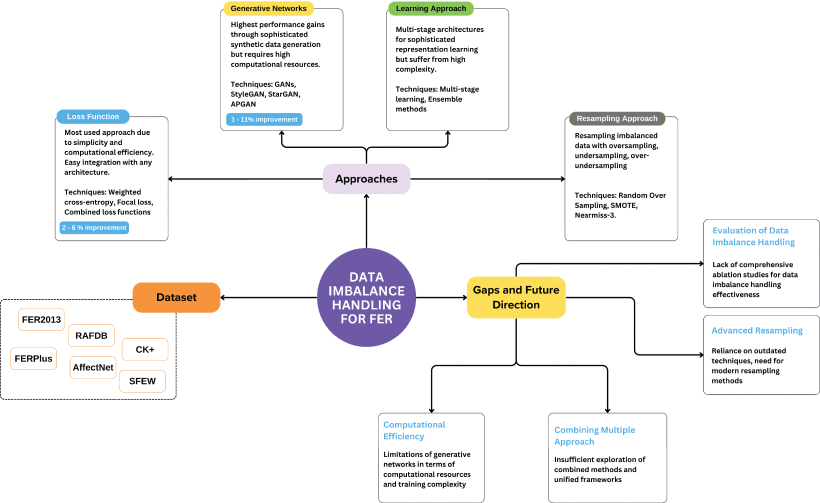
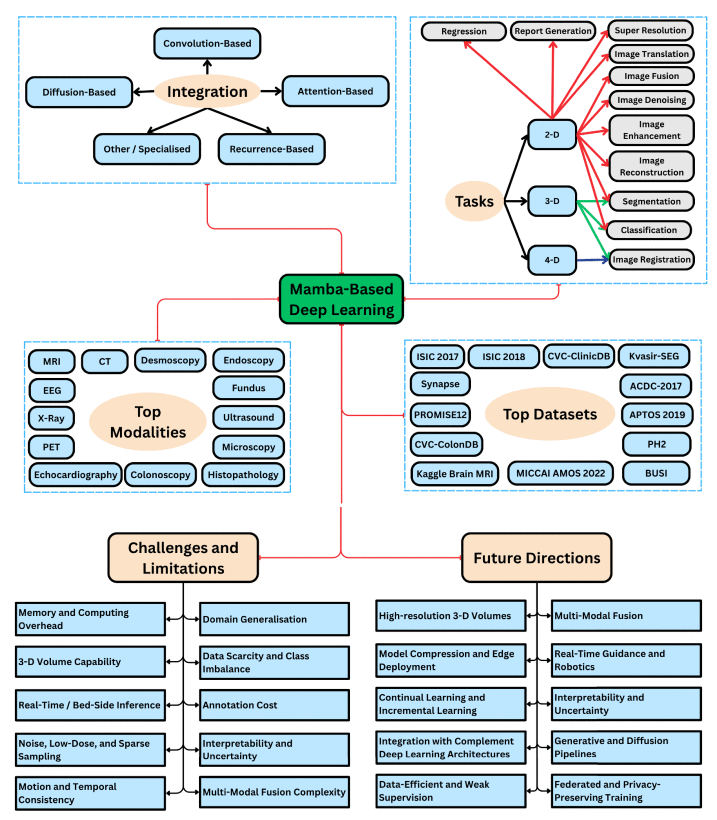
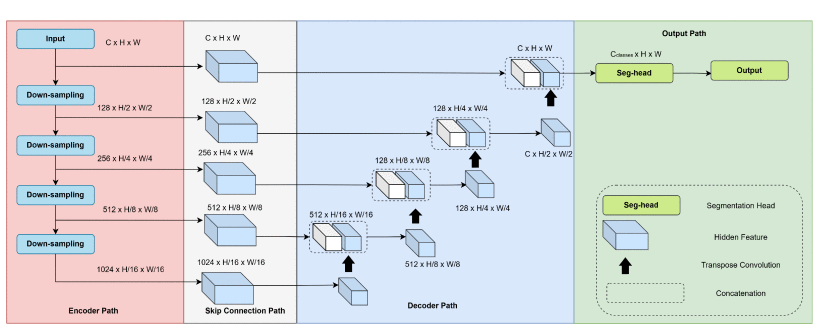
This systematic literature review charts about Mamba research in medical imaging. A preregistered Scopus search followed by strict quality appraisal yielded 85 peer-reviewed papers. Evidence shows that Mamba-enhanced networks have been applied to eleven tasks: regression, radiology-report generation, super-resolution, image translation, fusion, denoising, enhancement, reconstruction, segmentation, classification, and registration, with segmentation dominating the corpus. Fourteen imaging modalities are represented: MRI, computed tomography, dermoscopy, endoscopy, and fundus photography appear most frequently, confirming the architecture’s versatility across clinical domains. Mamba usually integrates with five patterns strategy. Convolution–Mamba hybrids remain the workhorse, while attention and diffusion-based variants lower GPU memory and sampling cost. Recurrence-augmented designs and specialised pairings with graph, spiking-neuron, or physics-informed modules address motion, temporal coherence, or energy efficiency. Despite these advances, studies converge on five critical limitations: 1) memory and computation overhead, 2) poor scalability to full 3-D volumes, 3) unmet real-time or bedside latency, 4) vulnerability to noise, low-dose, and sparse sampling, and 5) instability under respiratory or cardiac motion. Future work consistently points to: high-resolution 3-D pipelines that preserve Mamba’s linear complexity; aggressive model compression for edge deployment; robust domain generalisation with continual learning; tighter coupling with complementary deep-learning architectures to encode structural or physical priors; and data-efficient training that exploits weak labels and synthetic augmentation. Addressing these directions will translate Mamba from a promising sequence backbone into a reliable, resource-aware engine for diagnostic, interventional, and robotic imaging workflows.